

สมการถดถอยแบบพหุนามอาจเป็นการวิเคราะห์ที่ทำให้สับสนได้ อันเนื่องมาจากการเพิ่มจำนวนตัวแปรลงในตัวแบบ เป็นเรื่องที่ทำได้ไม่ยาก ทั้งนี้อาจเป็นเพราะเราต้องการให้มันอยู่ในตัวแบบหรือ เป็นเพราะเรามีข้อมูลของมันอยู่ในมือ สำหรับ ตัวแปรทำนายบางตัวที่มีนัยสำคัญ ซึ่งอาจมีนัยสำคัญเพราะความสัมพันธ์ของตัวแปรจริงๆหรือเพราะเหตุบังเอิญคุณสามารถทำเพิ่มพจน์พหุนามที่มีดีกรีลำดับสูงขึ้น เพื่อทำให้เส้นมีความบิดโค้ง สมรูปกับข้อมูลได้ตามความเหมาะสม แต่ในการทำเช่นนั้นต้องดูด้วยว่ากำลังทำเพื่อเชื่อมต่อจุดข้อมูลทั้งหมด หรือ ทำให้ได้ตัวแบบที่แท้จริง ทั้งนี้ในการทำแบบนี้จะทำ ให้ค่า R-squared ที่มี มีค่าเพิ่มขึ้น และอาจทำให้คุณสับสนโดยการเพิ่มพจน์ตัวแปรลงไปในตัวแบบ
จากบทก่อน ได้แสดงให้เห็นว่า ค่า R-squared อาจทำให้ตีความผิด(R-squared can be misleading)ได้ เมื่อถึงตอนวิเคราะห์ความสมรูปของตัวแบบ (goodness-of-fit) สำหรับตัวแบบเส้นตรงในสมการถดถอย ซึ่งเราได้แสดงให้เห็นว่าไม่ควรเพิ่มตัวแปรทำนายเกินความจำเป็น ลงในตัวแบบ ซึ่งมาถึงตอนนี้ ค่า adjust R-squared และ ค่า predicted R-squared อาจจะสามารถนำมาช่วยการศึกษา ตรงนี้ได้
ปัญหาบางประการเกี่ยวกับค่า R-squared
จากครั้งที่แล้ว เราแสดงให้เห็นแล้วว่า ค่า R-squared ไม่สามารถบ่งชี้ได้ว่า ตัวสัมประสิทธิ์ และการทำนายนั้นมีความ ลำเอียงเกิดขึ้นหรือไม่ ซึ่งทำให้เราต้องใช้แผนภาพเศษเหลือ (residual plots) มาร่วมในการประเมิน ดังนั้นจึงมีการนำค่า adjusted R – squared และ ค่า predicted R-squared มาช่วยแก้ปัญหาของ R-squared นี้
ปัญหาที่ 1 ทุกครั้งทีคุณทำการเพิ่มตัวแปรทำนายลงในตัวแบบ ค่า R – squared จะมีค่าเพิ่มขึ้นเสมอ ถึงแม้ว่าอาจจะ ไม่ทั้งหมด แต่จะไม่ทำให้ค่า R – squared ลดลงเลย และตัวแบบที่มีพจน์ตัวแปรเพิ่มขึ้นทำให้ตัวแบบนั้นมีความเหมาะสมกับ ข้อมูลมากขึ้น แต่เหตุผลที่ตัวแบบนั้นสมรูปกับข้อมูลเพิ่มขึ้น เพราะว่ามีพจน์ตัวแปรเพิ่มขึ้นในตัวแบบเท่านั้นเอง
ปัญหาที่ 2 ตัวแบบที่มีตัวแปรทำนายที่มากเกินไปและมีพจน์พหุนามกำลังสอง ตัวแบบจะเริ่มเก็บเอาผลของสิ่งรบกวน ของข้อมูลนั้นๆมารวมด้วย ซึ่งเงื่อนไขนี้ ทำให้ตัวแบบนั้นอาจทำให้มีค่า R–squared สูงขึ้นและทำให้เกิดความเข้าใจผิด(overfitting the model)ได้ และทำให้ตัวแบบนั้นใช้ในการทำนายได้มีประสิทธิภาพลดลง
ค่า adjusted R – squared คืออะไร
ค่า adjusted R – squared ใช้เปรียบเทียบความสามาถในการอธิบาย (Explanatory power) ของสมการตัวแบบ ที่มีจำนวนตัวแปรทำนายแตกต่างกัน
สมมติว่าคุณต้องการเปรียบเทียบตัวแบบที่มีตัวแปรทำนายจำนวน 5 ตัว ที่มีค่า R – squared สูงกับตัวแบบหนึ่งที่มี ตัวแปรทำนายหนึ่งตัว ในการเปรียบเทียบสองตัวแบบนั้น จะทำการหาว่าตัวแบบที่มีตัวแปรทำนาย 5 ตัวนั้น มีค่า R – squared สูงนั้นเพราะตัวแบบนั้นดีกว่าจริงๆ หรือเป็นเพียงเพราะมีจำนวนตัวแปรมากกว่า ซึ่งการเปรียบเทียบนี้จะใช้ ค่า adjusted R – squared เป็นตัวหาคำตอบ
ค่า adjusted R – squared จะเป็นการนำค่า R – squared มาปรับเพื่อให้สอดคล้องกับจำนวนตัวแปรทำนายที่อยู่ใน ตัวแบบ ค่า adjusted R – squared จะมีค่าเพิ่มขึ้นจากเดิมก็ต่อเมื่อพจน์ที่เพิ่มเข้ามาใหม่นั้นทำให้ตัวแบบอธิบายความได้ดีขึ้น จากค่าความคลาดเคลื่อน และค่า adjusted R – squared จะมีค่าลดลงถ้าพจน์ที่เพิ่มเข้ามาในตัวแบบนั้นทำให้ตัวแบบอธิบาย ความได้น้อยกว่าค่าความคลาดเคลื่อน ค่า adjusted R – squared ยังสามารมีค่าเป็นลบได้ แต่โดยทั่วไปแล้วจะไม่เป็นเช่นนั้น แต่อย่างหนึ่งคือ จะมีค่าน้อยกว่า ค่า R – squared เสมอ
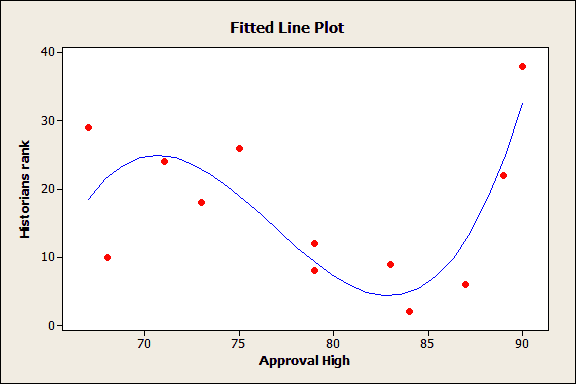
เพื่อทำให้เข้าใจได้ง่ายขึ้น มาลองดูตัวอย่าง ผลลัพธ์ของการวิเคราะห์ถดถอยตามนี้ จะเห็นว่า ค่า adjusted R – squared ที่มีค่าสูงสุดอยู่ที่ตำแหน่งไหน และมีค่าลดลงเมื่อมีการพจน์ตัวแปรทำนายเพิ่มขึ้น ในขณะที่ ค่า R – squared ยังมีค่าเพิ่มขึ้นเรื่อยๆ
จากผลลัพธ์นี้ จะทำให้เห็นว่าตัวแบบที่ดีน่าจะมีจำนวนตัวแปรทำนาย 3 ตัวเท่านั้น จากบทความที่แล้ว แสดงให้เห็น ว่าตัวแบบที่เป็นแบบ under-specified (ที่มีรูปตัวแบบอย่างง่าย และมีตัวแปรที่มีอทธิพลต่อค่าตอบสนองแต่ไม่ได้ครอบคลุมไว้ ในตัวแบบ) อาจทำให้ค่าทำนายนั้นเป็นค่าประมาณที่มีความลำเอียง (bias estimate) แต่ถ้าตัวแบบเป็นแบบ over specified (ตัวแบบมีความซับซ้อน กล่าวคือ มีตัวแปรที่ไม่ได้มีอิทธิพลต่อค่าตอบสนองรวมอยู่ในตัวแบบด้วย) อาจทำให้ความเที่ยงตรง ของค่าสัมประสิทธิ์และค่าทำนายมีค่าลดลง และโดยความเป็นจริงแล้ว เราต้องการตัวแบบที่มีเฉพาะพจน์ของตัวแปรทำนาย ที่มีความสำคัญจริงๆเท่านั้น (อ่านตัวอย่างได้ที่บทความ Using Minitab’s Best Subsets Regression)
สุดท้ายความแตกต่างการใช้ adjusted R-squared คือสิ่งที่แสดงในค่า unbiased estimate of the population R-squared

ค่า Predicted R – squared คืออะไร
ค่า Predicted R – squared จะเป็นตัวบ่งชี้ว่าตัวแบบที่เรามีนั้นสามารถทำนายค่าตอบสนองค่าใหม่ได้ดีขนาดไหน ตัวสถิตินี้จะสามารถช่วยบอกว่าตัวแบบของเรานั้นเป็นเพียงตัวแบบที่สมรูปกับข้อมูลแต่มีไม่มีความสามารถในการทำนายค่า ตอบสนองของข้อมูลค่าใหม่ (อ่านตัวอย่างเพิ่มเติมได้จากบทความเรื่อง using regression to make predictions.)
Minitab จะทำการคำนวณค่า Predicted R – squared อย่างเป็นขั้นเป็นตอน โดยการหักข้อมูลที่สังเกตได้ออกจาก ชุดข้อมูลทีละตัว แล้วทำการประมาณสมการถดถอย จากนั้นทำการหาว่าตัวแบบนั้นให้ผลค่าทำนายของข้อมูลที่หักออกไป นั้นได้ดีอย่างไร ซึ่งค่า Predicted R – squared นั้น สามารถมีค่าเป็นลบได้ เช่นเดียวกันกับค่า adjusted R – squared และยังมีค่าน้อยกว่าค่า R – squared เสมอ
ถึงแม้ว่าคุณอาจจะไม่ได้นำตัวแบบนี้เพื่อไปใช้ในการทำนายค่าตอบสนอง ค่า Predicted R – squared ก็ยังให้สาระช้อมูลที่ดีต่อคุณ
ประโยชน์ที่สำคัญของค่า Predicted R – squared คือ การป้องกันที่จะทำให้คุณสร้างตัวแบบเป็นแบบ over specified ซึ่งมีจำนวนตัวแปรทำนายเกินความจำเป็น และทำให้ตัวแบบนั้นมีความคลาดเคลื่อนเกิดขึ้นได้
เพราะว่ามันเป็นไปไม่ได้ที่จะทำนายความคลาดเคลื่อน ค่า Predicted R – squared จะลดลงเมื่อเกิด Overfit model ถ้าคุณเห็นค่า Predicted R – squared ที่มากแต่น้อยกว่าค่า R-squared ปกติ คุณเกือบมั่นใจเทอมส่วนใหญ่ในโมเดล
ตัวอย่างของตัวแบบ over specified และค่า Predicted R – squared
คุณสามารถทดลองกับตัวอย่างนี้ได้ด้วยตัวเองโดยการใช้ Minitab กับไฟล์ project file ซึ่งมีข้อมูลอยู่ 2 แผ่นงาน สามารถdownload ได้จาก Minitab 30-day trial version
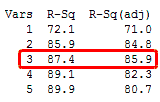
มีวิธีง่ายๆในการดูว่า ตัวแบบนั้นเป็นแบบ over specified หรือไม่ ในการวิเคราะห์ตัวแบบเส้นตรงถดถอยที่มีตัวแปร ทำนายที่ทีแต่ละตัวมี degree of freedom เท่ากับ 1 คุณจะได้ค่า R – squared เท่ากับ 100% เสมอ
ในแผ่นงาน ทำการสร้างข้อมูลขึ้นมา 10 แถว สำหรับค่าตอบสนองจำนวน 10 ค่า และตัวแปรทำนายจำนวน 9 ตัว และในตัวแปรทำนายทั้ง 9 ตัวนี้ และมี degree of freedom เท่ากับ 9 เราจะได้ค่า R – squared เท่ากับ 100%
จากผลนี้เราจะเห็นเหมือนกับว่าตัวแบบนี้สามารถอธิบายความผันแปรที่เกิดขึ้นได้ทั้งหมด อย่างไรก็ดีเราจะรู้ว่าตัวแปร ทำนายอย่างสุ่มนี้จะไม่มีความสัมพันธ์ใดใดกับค่าตอบสนองอย่างสุ่มเลย เพราะเราทำการทดลองหาความเหมาะสมผ่านค่า ความผันแปรแบบสุ่ม
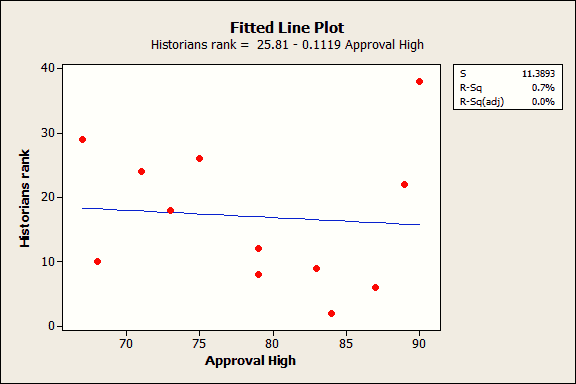
จากตัวอย่างนี้เป็นตัวอย่างที่มีลักษณะไม่ปกติ ที่นี้ลองมาดูกรณีข้อมูลจริงบ้าง ตัวอย่างการจัดอันดับ president ซึ่ง ข้อมูลอยู่ในไฟล์ great presidents ซึ่งเราพบว่าไม่มีความสัมพันธ์ระหว่างค่า approval rating ของ president ที่มีค่าสูงสุด กับ ค่าอันดับในอดีต ซึ่งเราสามารถอธิบายได้ว่า เส้นที่ลากในแผนภาพนั้น เป็นตัวอย่างที่แสดงให้เห็นว่าข้อมูลไม่มีความสัมพันธ์ ใดใดและเส้นตรงนี้ให้ค่า R – squared เท่ากับ 0.7%
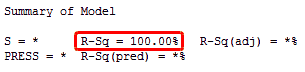
สมมติว่าเราทำการปรับตัวแบบจนเป็นแบบ over-specified ด้วยการเพิ่มพจน์พหุนามกำลังสาม (Cubic polynomial) ซึ่งได้ผลลัพธ์ตามแผนภาพด้านล่าง
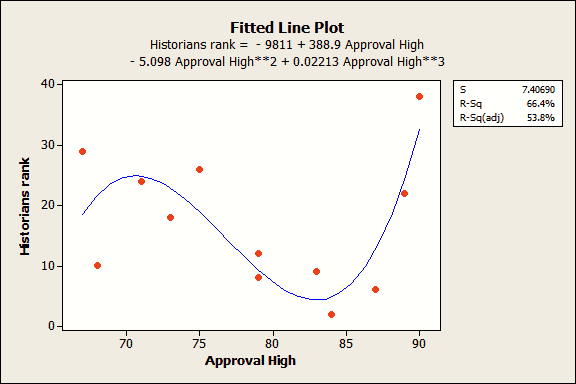

จะเห็นว่า ทั้งค่า R-squared และ ค่า adjusted R-squared มีค่าดูดีมาก รวมทั้งค่าสัมประสิทธิ์ทุกตัวก็มีนัยสำคัญ เพราะค่า p-value ทุกตัวมีค่าน้อยกว่า 0.05 และแผนภาพเศษเหลือ (residual plots) ในที่นี้ไม่ได้แสดงไว้ ก็ให้ผลลัพธ์ที่ดูดี เช่นกัน
ในการทำเช่นนี้ คือเราทำให้เส้นมีความโค้งงอไปเพื่อเชื่อมจุดข้อมูลอย่างต่อเนื่อง แทนที่จะทำการหาความสัมพันธ์ ที่แท้จริงของตัวแปรแต่ละตัว
ตัวแบบที่เราได้มาจะมีความซับซ้อนและค่า predicted R-squared ก็ให้ผลที่ต่างออกไป ซึ่งมีค่าเป็นลบ และสามารถ แปลความได้ว่า ถ้า 0% แปลว่าไม่ดี ดังนั้นค่าที่ติดลบยิ่งแย่ลงไปอีก
ค่า predicted R-squared ที่เป็นลบไม่ได้หมายความว่า ตัวแบบนั้นเป็นแบบ over specified เสมอไป แต่ถ้าเมื่อไหร่ ก็ตามที่คุณเริ่มเห็นว่า ค่า predicted R-squared เริ่มมีค่าลดลง ทุกครั้งที่มีการเพิ่มพจน์ตัวแปรทำนายลงในตัวแบบ เว้นแต่ ตัวแปรทำนายนั้นจะมีผลเป็นนัยสำคัญ ไม่เช่นนั้นการเพิ่มตัวแปรทำนายนั้นอาจทำให้ตัวแบบกลายเป็น over specified
บทสรุปเกี่ยวกับค่า adjusted R-squared และค่า predicted R-squared
ข้อมูลทุกตัวมีค่าความผันแปรที่ไม่สามารถอธิบายรวมอยู่ด้วยเสมอ ซึ่งค่า R-squared นี้ไม่ได้บอกไว้ว่าค่าสูงสุด ที่ควรเป็นอยู่ตรงไหน การปรับแต่งค่า R-squared ให้มีค่าเพิ่มขึ้น จึงอาจเป็นเพียงแค่การเพิ่มตัวแปรทำนายเพื่อให้อธิบาย ในสิ่งที่ไม่สามารถอธิบายได้
ในกรณีนี้ คุณจะได้ค่า R-squared สูงขึ้น แต่อาจทำให้เกิดผลที่ผิดพลาดได้ และลดความเที่ยงตรง และทำให้ความสามารถในการทำนายลดลงด้วย
ซึ่งค่า adjusted R-squared และค่า predicted R-squared จะทำให้คุณสามารถ ประเมินได้ว่าตัวแปรทำนายกี่ตัวที่ควรจะอยู่ในตัวแบบ
- ใช้ค่า adjusted R-squared เพื่อเปรียบเทียบตัวแบบที่มีจำนวนตัวแปรทำนายไม่เท่ากัน
- ใช้ค่า predicted R-squared เพื่อบ่งชี้ว่าตัวแบบนั้นสามารถทำนายค่าตอบสนองของข้อมูลใหม่ได้ดีอย่างไรและ ตัวแบบนั้นมีความซับซ้อนเกินไปหรือไม่
การวิเคราะห์การถดถอยเป็นเครื่องมือที่มีประโยชน์มาก แต่จะต้องใช้ให้ถูกต้องและไม่หลงไปกับหลุมพรางบางข้อที่กล่าวมา
ถ้าคุณกำลังเรียนรู้เกี่ยวกับเรื่อง Regression, เข้าไปอ่าน regression tutorial ของฉัน

บทความต้นฉบับ : Multiple Regression Analysis: Use Adjusted R-Squared and Predicted R-Squared to Include the Correct Number of Variables
ต้นฉบับนำมาจาก Minitab blog, แปลและเรียบเรียงโดยสุวดี นำพาเจริญ,
บริหารจัดการ SCM Blog โดยชลทิชา จำรัสพร บริษัท โซลูชั่น เซ็นเตอร์ จํากัด ตัวแทน Minitab ในประเทศไทย

เพิ่มเติมเกี่ยวกับบริษัท Minitab
Minitab ช่วยให้บริษัทและองค์กรต่างๆ สามารถมองเห็นแนวโน้มของข้อมูล, แก้ปัญหาและค้นพบประเด็นสำคัญจากข้อมูลเชิงลึก โดยนำเสนอชุดโซลูชั่นที่ครอบคลุมทุกด้านและดีที่สุดสำหรับซอฟต์แวร์ในระดับเดียวกัน ที่ใช้สำหรับการวิเคราะห์ข้อมูลและการปรับปรุงกระบวนการ
ด้วยวิธีการที่เป็นเอกลักษณ์ และการนำเสนอซอฟต์แวร์และบริการแบบองค์รวม Minitab ช่วยให้องค์กรเข้าถึงกระบวนการตัดสินใจในส่วนที่ช่วยผลักดันให้เกิดความเป็นเลิศทางธุรกิจได้ดีขึ้น ความง่ายในการใช้งานที่โดดเด่นกว่าใครมีส่วนช่วยให้ Minitab สามารถทำให้การเข้าถึงข้อมูลเชิงลึกเป็นเรื่องที่ง่าย ทีมงานของ Minitab ซึ่งประกอบด้วยผู้เชี่ยวชาญทางด้านการวิเคราะห์ข้อมูลที่ได้ผ่านการอบรมมาเป็นอย่างเข้มงวด จะช่วยให้ผู้ใช้งานมั่นใจว่าจะได้รับประโยชน์สูงสุดจากการใช้งานวิเคราะห์ข้อมูลและพร้อมที่จะให้คำปรึกษาตลอดเวลาที่ใช้งานเพื่อนำไปสู่การตัดสินใจที่ดีขึ้น รวดเร็ว และแม่นยำ
เป็นเวลากว่า 50 ปีที่ Minitab ได้ช่วยองค์การต่าง ๆ เพิ่มรายได้ ควบคุมและลดต้นทุน เพิ่มคุณภาพ เสริมสร้างความพึงพอใจของลูกค้า และเพิ่มประสิทธิภาพ ธุรกิจและองค์นับหมื่นทั่วโลกใช้ Minitab Statistical Software®, Companion by Minitab®, Minitab Workspace®, Salford Predictive Modeler® and Quality Trainer® เป็นเครื่องมือช่วยในการค้นพบและปรับปรุงความบกพร่องในกระบวนการ